[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[3]
전제조건
실습과정 미리보기
- AWS Glue ETL을 사용하여 데이터를 처리하고 결과를 다시 S3에 저장
- Glue 개발 엔드포인트와 Sagemaker 노트북을 사용하여 데이터 변환 단계를 진행(PySpark)

| 서비스명 | 서비스 설명 | 비고 |
| AWS Glue dev endpoint | AWS Glue 스크립트를 개발하고 테스트할 수 있는 환경 | 엔드포인트가 데이터 스토어에 액세스한 후 개발 엔드포인트에 연결하는 노트북을 생성. 노트북을 사용하여 ETL 스크립트를 작성하고 테스트할 수 있습니다. |
| AWS SageMaker | jupyter notebook과 동일한 환경이나 aws 클라우드 플랫폼 |
1. AWS Glue Dev Endpoint 생성
PySpark를 사용하여 Glue ETL 스크립트를 대화식으로 개발하기 위해 AWS Glue Dev Endpoint를 생성

Data catalog - add endpoint 클릭

- name : analyticsworkshopEndpoint1
- role : AnalyticsworkshopGlueRole
- Data processing units (DPUs): 2 (이렇게 하면 이 실습을 실행하는데 드는 비용이 절감됩니다)
- 네트워킹 : 디폴트값
- ssh public key : 디폴트값

새로운 Glue 개발 엔드포인트가 가동되는데 몇 분(6-10 분)이 걸립니다.
상태가 PROVISIONING에서 READY로 변경되는 것을 볼 수 있습니다.
다음 단계 전까지 이 작업을 기다려야합니다.

2. Glue endpoint 용 SageMaker 노트북 (Jupyter) 생성
SageMaker 노트북 (Jupyter) 생성합니다.


name : analyticsworkshopNotebook
endpoint : analyticsworkshopEndpoint1 (방금 생성한 엔드포인트)
role : create an IAM role을 선택하여 권한을 생성합니다. 하단 이름 : workshop
그 외의 값 : 디폴트 값으로 설정하고 create note book 클릭

몇 분(4-5 분) 소요됩니다: 노트북 생성 상태가 Starting에서 Ready로 변경 될 때까지 기다립니다.

3. Jupyter 노트북 실행
생성한 노트북을 실행 하기 전 analytics-workshop-notebook.ipynb 을 로컬에 다운 받습니다.
다운 한 후 노트북을 실행
실행 한 후 로컬에 다운받은 파일을 업로드합니다.

- 업로드 된 파일 클릭시노트북의 오른쪽 상단에 'Sparkmagic (PySpark)' 이라고 표시되어 있는지 확인합니다.
- 노트북의 내용을 실행합니다.

4. 가공/변경된 S3 데이터 확인

- .parquet 파일들이 폴더에 생성 되었는지 확인합니다.
현재 과정 되짚어보기
Glue 개발 엔드포인트와 Sagemaker 노트북을 사용하여 데이터 변환 단계를 진행(PySpark)하였다.
(추가 - 참고 항목)
Sagemaker를 활용하여 직접 코드로 변환한 작업을 Glue Studio의 그래픽 인터페이스를 사용하여 코드리스로 데이터 변환. 데이터 변환 워크플로우를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 실행 가능
| 서비스명 | 서비스 설명 | 비고 |
| Glue Studio | Glue Studio의 그래픽 인터페이스를 사용하여 데이터 변환을 함 (코드리스) |
실습 과정 미리보기
- AWS Glue에서 ETL (추출, 변환 및 로드) 작업을 쉽게 생성, 실행 및 모니터링 할 수있는 그래픽 인터페이스인 AWS Glue Data Studio를 사용
1. Glue Studio 실행
Glue Studio 실행 후 좌측 바 jobs - blank canvas(빈 캔버스 부터 시작) - create 클릭
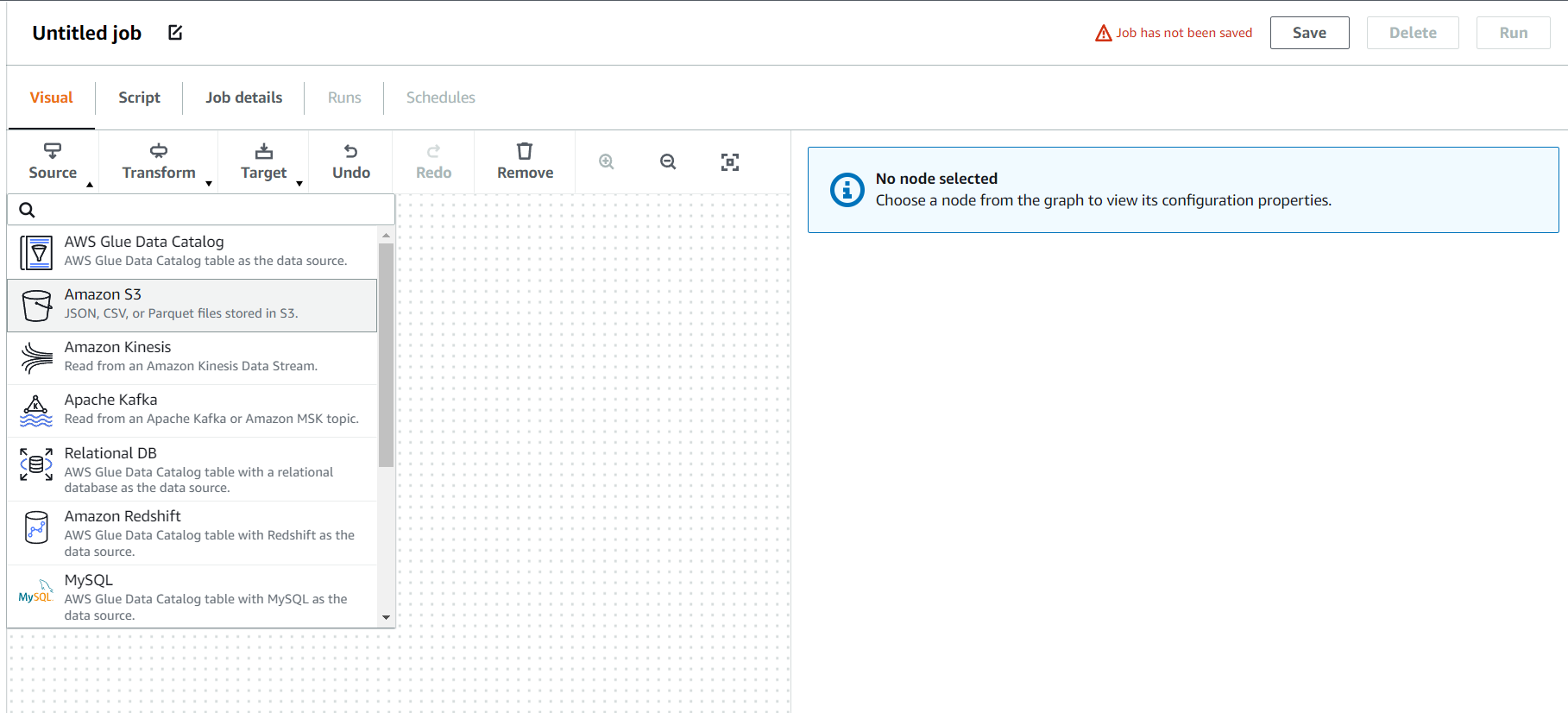
(1) Source - amazon S3 선택

data catalog table 을 이미 만들어 놓았기 때문에 data catalog table 선택
- database : analyticsworkshopdb
- table : raw
- 단, 이름을 바꾸어 줄 것임

node properties 탭에서 기존 name : amazon S3 을 'raw' 로 변경
(2) 같은 방법으로 reference_data 생성

(3) 두 테이블을 join 하기 위해 target tab - join 선택

node parents 드롭 박스에서 reference_data 테이블을 선택하여 두 데이터를 join 시킴
단, 어떤 열로 join 을 할지 정해주지 않았기 때문에 오류 발생

transform tab에서 조인 조건을 track_id 로 설정
단, raw 테이블의 track_id 는 int 형, reference_data의 track_id 는 string 형 임에도 조인에 성공한 것 주의
(4) 조인된 데이터의 정리를 위해 transform - apply mappping 작업

필요 없는 열 drop 하기

단 사진의 맨 위 track_id 가 int 형 인걸 볼 수 있는데, 이를 string으로 변환
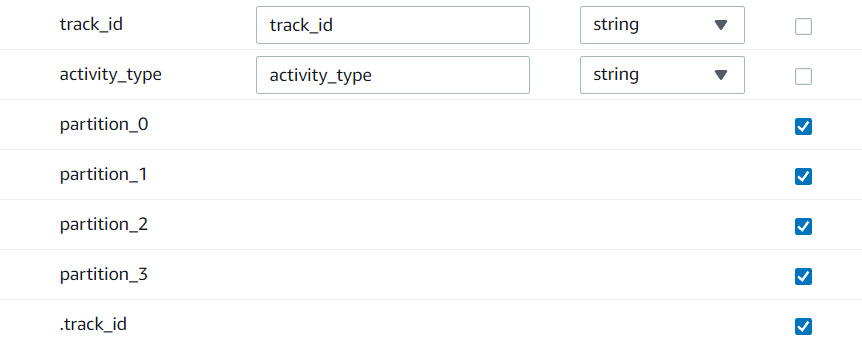
데이터 설정을 마쳤으니 저장 할 위치를 지정

(5) 변환된 데이터를 target-s3 버튼을 눌러 s3에 데이터를 저장

저장 포맷은 다음과 같음 (sagemaker의 실행 결과와 동일한 설정 단, 구분을 위해 processed-data2 버킷폴더에 저장)
- Format : parquet
- compression type : Snappy
- S3 target location : s3://hongwon-analytics-workshop-bucket/data/processed-data2/
- Data Catalog update options :
- Choose Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions
- Database: analyticsworkshopdb
- Table name: processed-data2
(6) 최종 설정을 위해 job detail 탭에서 name 과 iam role 을 지정

기타 세부설정은 다음과 같다


우측 하단의 RUN 버튼을 클릭해 코드리스로 데이터 변환을 시행
현재 과정 되짚어보기
sagemaker를 활용해 코드로 짠 작업을 Glue Studio 를 활용하여 코드리스 버전으로 실행
다음편 보러가기
2022.05.29 - [Specialist/AWS] - [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[4]
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[4]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[3] 실습과정 미리보기 Amazon Athena의 표준 SQL 쿼리를 사용하여 Glue 카탈로그에 등록된 데이터를 탐색 Athena를 사용하여 Amazon Qui
khw742002.tistory.com