Generalist/data engineering
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[6]
홍원
2022. 5. 30. 14:42
전제조건
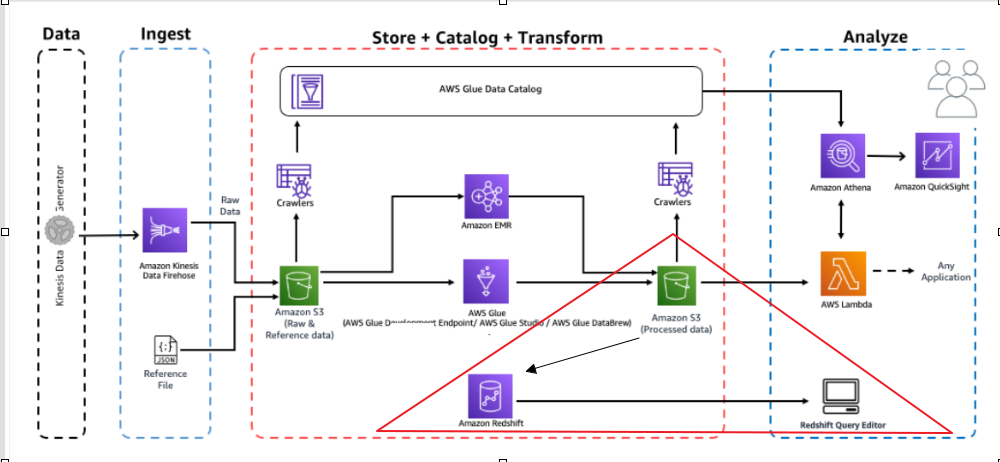
실습과정 미리보기
- Amazon Redshift 클러스터를 설정하고 S3 데이터를 Amazon Redshift로 로드
1. Redshift IAM Role 생성
이 단계에서는 Redshift 클러스터를 위한 IAM Role을 생성합니다.
- Create role 클릭
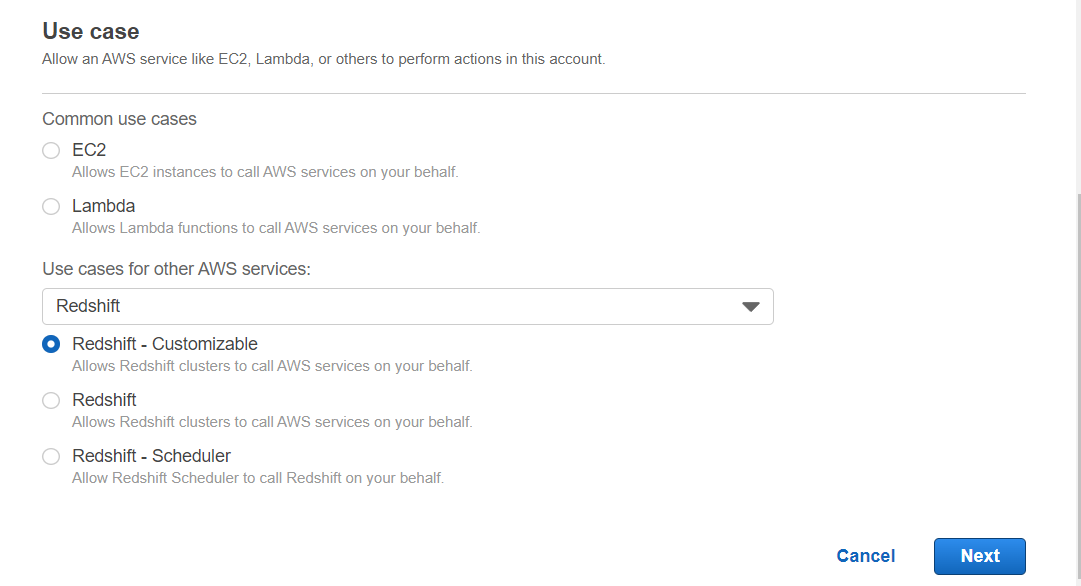
- Redshift 선택
- Select your use case 아래의 Redshift - customizable 선택
- Next: Permissions 클릭
검색 박스에서 정책을 검색 및 선택
- AmazonS3FullAccess
- AWSGlueConsoleFullAccess (워크샵에서는 glue에 접근하기에 필요합니다.)
- Next: Review 클릭
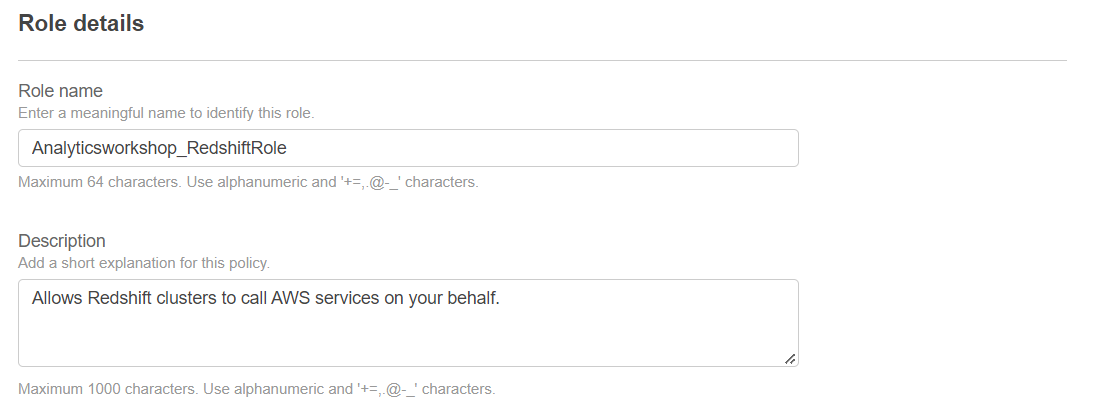
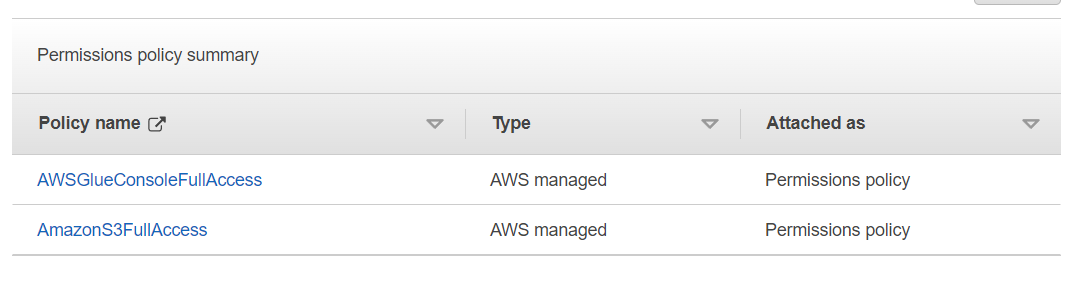
- Role Name: Analyticsworkshop_RedshiftRole
- 설정 한 두 정책 한번 더 확인
2. Redshift 클러스터 생성
이 단계에서는 2 노드 Redshift 클러스터를 생성하여 작은 스타 스키마 데이터베이스를 생성합니다.
- Create Cluster 클릭
- Cluster identifier 는 redshift-cluster-1 으로 남겨둡니다
- Node Type 으로 dc2.large 선택
- Nodes 수를 2로 입력
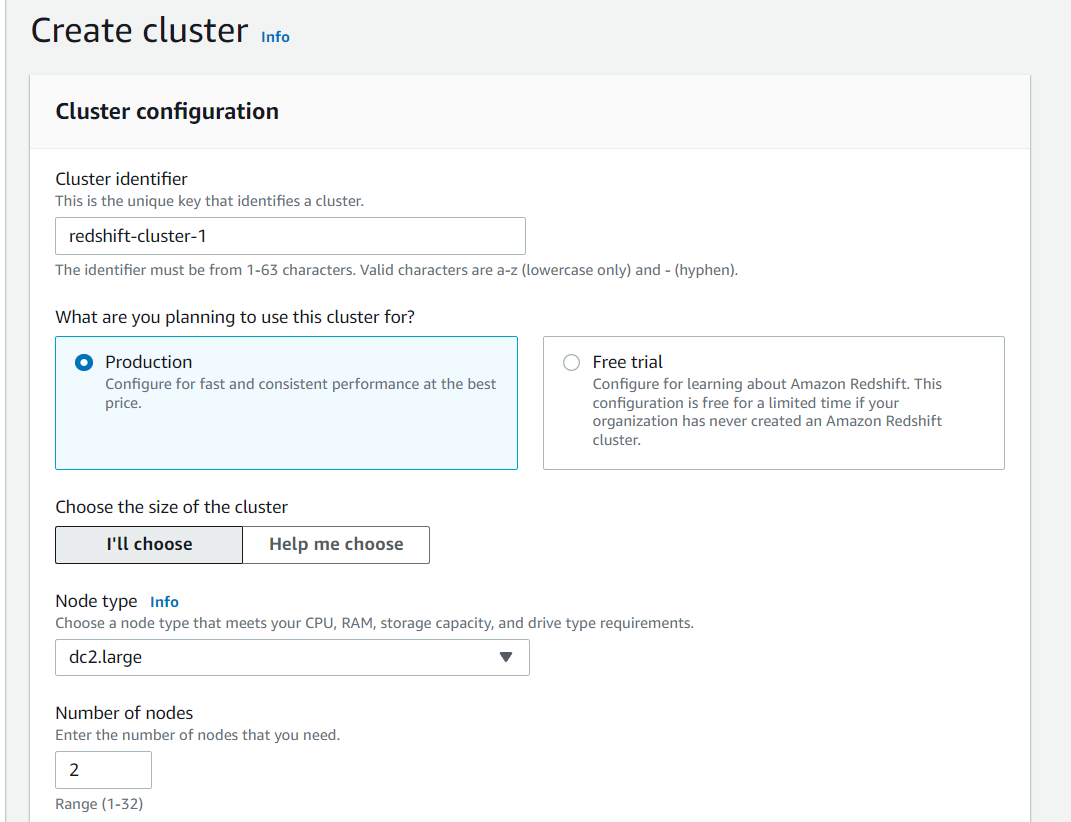
- Configuration summary 확인
- Database port (optional) 은 5439 로 남겨둡니다
- Master user name 을 admin 으로 변경
- Master user password 입력
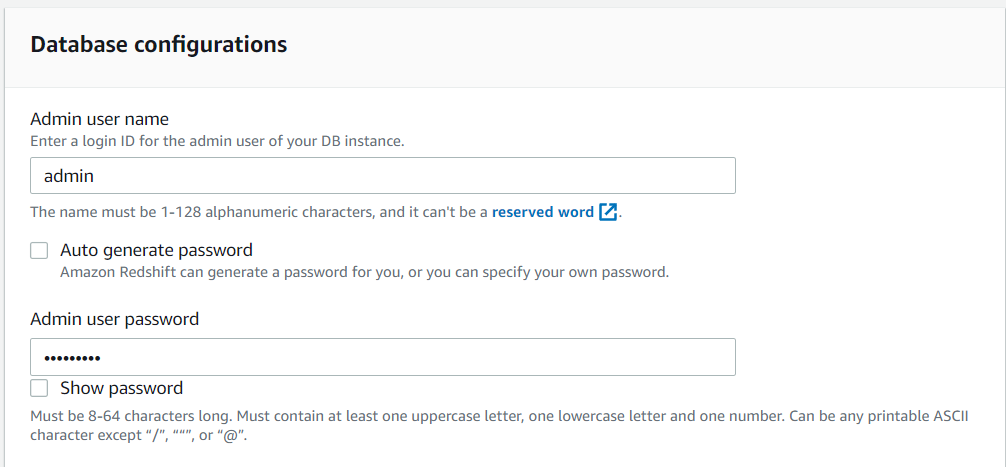
- 드롭 다운 메뉴에서 이전에 생성 한 Analyticsworkshop_RedshiftRole을 선택합니다.
- Associate IAM role 클릭
- Analyticsworkshop_RedshiftRole Role이 Associated IAM roles 아래에 나와야 합니다.
- Cluster permissions (optional) 확장
- Additional configurations 은 기본값으로 남겨둡니다. 기본 VPC 및 기본 Security Group을 사용합니다.
- Create Cluster 클릭.
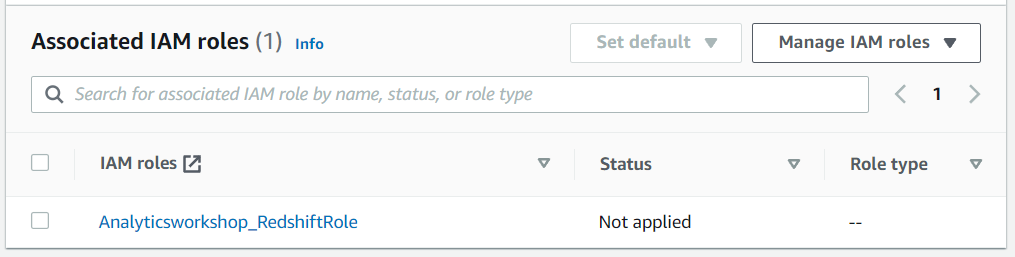
클러스터가 가동되고 Available 상태가되면 다음 단계로 이동(5분 정도 소요됨)
status 가 modyfies --> available 로 변경 까지 기다림

3. 레드시프트 내 데이터 적재를 위한 설정
클러스터 이름을 클릭합니다.

- connet to database 클릭

- 위와 같이 설정 한 뒤 connet 클릭
4. 레드시프트 내 테이블 생성 후 S3에서 데이터 불러오기
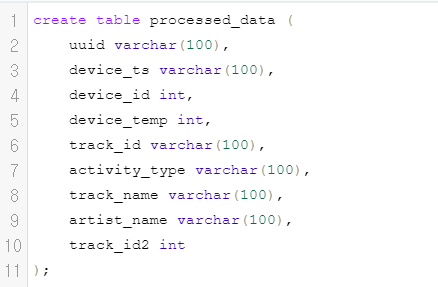
copy 명령어를 통해 s3에서 데이터 불러오기

현재 과정 되짚어보기
Amazon Redshift 클러스터를 설정하고 S3 데이터를 Amazon Redshift로 적재해보았습니다.
다음편 보러가기
2022.05.30 - [Specialist/AWS] - [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[마무리]
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[마무리]
이번 워크샵을 통해 AWS 서비스를 사용하여 데이터 추출,적재,변환,분석의 전반적인 과정을 경험하였습니다. AWS의 각 서비스가 어떠한 역할을 하는지 알고, 이를 조합하여 데이터 파이프라인을
khw742002.tistory.com