Pycaret이란?
scikit- learn 패키지를 기반으로, 자동으로 머신러닝 모델을 만들어 주는 파이썬 라이브러리.
몇줄의 코딩으로 쉽게 모든 모델 비교, 하이퍼파라미터 튜닝등을 할 수 있다.
머신러닝 모델 구축에 항상 어려움이 있었다면 Pycaret을 적극적으로 활용해보자!
데이터 준비
전자상거래 웹사이트 내 거래 데이터를 사용해 불법거래를 예측하는 기계학습 모델을 구축하기 위해
Electronica 전자제품 판매 사이트에서 제공된 유저의 첫번째 트렌젝션 정보 데이터(Fraud_Data)를 사용

- user_id : 유저 아이디
- signup_time : 유저가 계정을 생성 시각
- purchase_time : 유저가 상품을 구매한 시각
- device_id : 트랜젝션별 고유한 디바이스 아이디
- source : 유저가 웹사이트에 접속한 경로
- browser : 유저가 사용한 인터넷 브라우저
- sex : 유저의 성별
- age : 유저의 나이
- ip_address : 유저의 IP 주소
- class : 사기거래 여부 (정상거래 : 0, 사기거래 : 1)
EDA
- 'purchase_time' 과 'signup_time' 열의 '월'을 추출하여 class 별 히스토그램 그리기 - 'p_mth','s_mth' 열 생성

각각 1월에 가장 사기거래(주황색) 빈도가 높음
- 'purchase_time' 과 'signup_time' 열의 '일'을 기준으로 두 데이트타임의 차를 구함 - 'DTH' 열 생성

가입하자마자 구매했을 경우 사기거래의 빈도가 높았음
- device_id 별 user_id 의 수를 구하여 class 값 확인 - 'd_ct' 열 생성
- ip_address별 user_id 의 수를 구하여 class 값 확인 - 'ip_ct' 열 생성
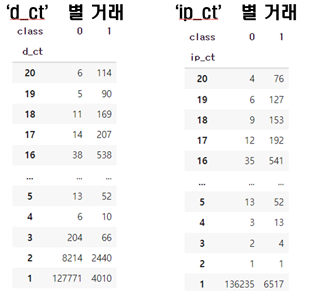
각각 동일 디바이스, 아이피로 유저 아이피가 생성되었을 경우 그 수가 많을 수록 사기거래의 빈도가 높음
분석 데이터 셋 확인
- EDA를 통해 생성한 열과 class 열을 사용하여 분석 데이터 셋 구축 - output.csv 파일로 생성

Pycaret 설치 및 기초 설정
import numpy as np #넘파이 임포트
import pandas as pd #판다스 임포트
!pip install pycaret -q #파이케럿 설치
!pip install markupsafe==2.0.1 -q #html markup #문자열의 이스케이프 처리를 안전하게 해주는 패키지 설치
!pip install Jinja2 #파일을 html로 만들어주는 패키지 설치
from pycaret.utils import enable_colab
enable_colab() #코랩에서 사용 가능하도록 pycaret.utils 임포트
from pycaret.classification import * #파이케럿의 분류 모델을 모두 임포트
from google.colab import drive
drive.mount('/content/drive') #본인 구글 드라이브 마운트
%cd /content/drive/MyDrive/Colab Notebooks/ #경로 설정
data = pd.read_csv('output.csv') #분석용 데이터 셋 불러오기- Pycaret 사용을 위한 설치 패키지와 분석용 데이터 셋을 불러옴
모델링
1. SETUP
exp = setup(data, silent=False, target='class',numeric_features=['d_ct', 'ip_ct'], normalize=True)
#데이터 : data
#타겟 : class 열
#numeric_features : d_ct, ip_ct 열을 숫자형 열로 인식 시키기 위해 설정 (안할시 카테고리 열로 인식함)위 코드를 통해 분석 세팅을 하면 Pycaret이 아래 결과처럼 자동으로 세팅

2. 모델 비교
compare_models()파이케럿의 가장 강력한 기능인 compare_models를 사용하여 위 기초설정에서 import 한 분류 모델을 모두 비교
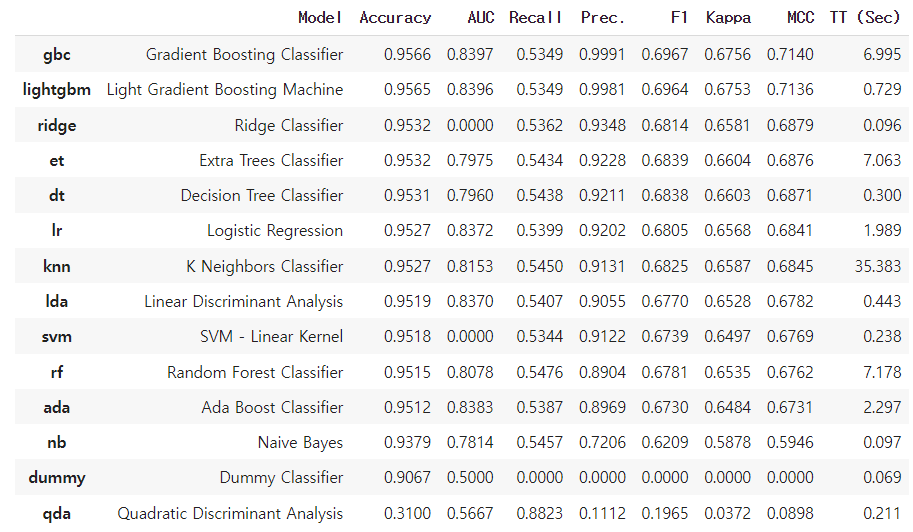
- gbc 모델이 가장 정확도가 높았음(0.9566). - 간단하게 모든 머신러닝 모델의 성능을 비교 성공
3. 모델 생성
model = create_model('gbc')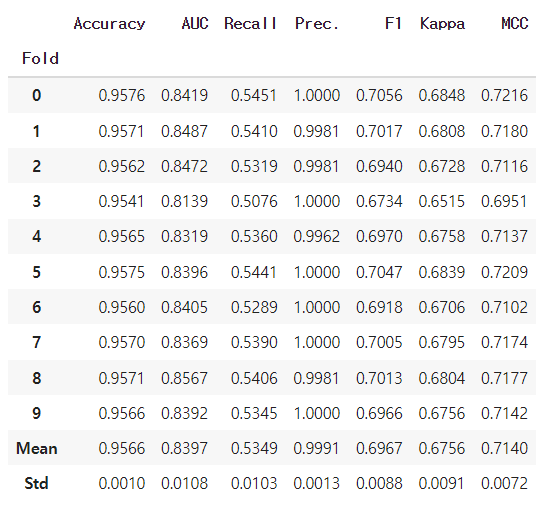
tuned_model = tune_model(model)생성한 모델의 하이퍼 파라미터 튜닝 역시 간단하게 할 수 있습니다.

AUC가 튜닝을 통해 개선되었습니다.
4. 성능 확인
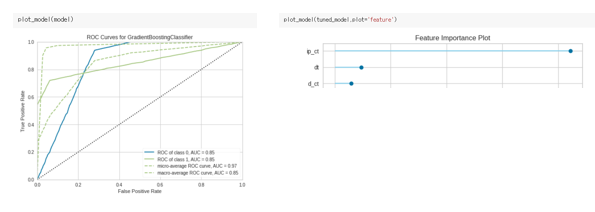
plot_model사용 하여 성능 확인 까지 간단하게 가능합니다.
이번 글에서는 Pycaret 을 사용하여 간단하게 머신러닝 모델 구축 하였습니다.
Pycaret 정말 좋네요 최고입니다!
더 자세한 분석 및 모델링이 궁금하다면 아래 링크에서 확인해 주세요!
EDA 및 모델링 과정(블랜딩 기법), 성능 비교(비용고려)를 활용한 방법을 깃허브에 공개하였습니다.
GitHub - hongwon2/Python-Practice: 데이터분석을 위한 파이썬 연습 레파지토리입니다.
데이터분석을 위한 파이썬 연습 레파지토리입니다. Contribute to hongwon2/Python-Practice development by creating an account on GitHub.
github.com
'Generalist > data science' 카테고리의 다른 글
| 가짜뉴스 분류 모델(RNN, LSTM, GRU, CNN-LSTM) (1) | 2022.12.11 |
|---|

댓글