RFM이란?
회사 매출에 가장 중요한 인자를 R , F, M 으로 가정하여, 이 3가지 관점에서 고객의 가치를 분석하는 방법이다.
- R - Rencency : 최근 구매일
- 최근 무언가를 구매한 사용자를 우량 고객으로 취급
- F - Frequency : 구매 횟수
- 사용자가 구매한 횟수를 세고, 많을수록 우량 고객으로 취급
- M : Monetary : 구매 금액 합계
- 사용자의 구매 금액 합계를 집계하고, 금액이 높을수록 우량 고객으로 취급
위 세 가지 지표를 집계한 뒤에 고객군 별로 속성을 정의한다.
마케팅, 기획 팀은 서비스 개선을 검토하고, 고객에게 메일 최적화, 쿠폰 제공 등 고객군 별 맞춤 전략을 짜야한다.
데이터 셋
캐글 - Superstore Sales Dataset을 정제한 데이터 셋.
https://www.kaggle.com/datasets/rohitsahoo/sales-forecasting

- SQL Tool : 구글 빅쿼리
- 테이블 명 : sale_data
- 열 수 : 7 열
- 행 수 : 9723 행
- Order_Date(date) : 주문 일자
- Order_id(string) : 주문 ID
- Customer_id(string) : 고객 ID
- Product_id(string) : 상품 ID
- Category(string) : 상품 카테고리
- Sub Category(string) : 상품 하위 카테고리
- Sale(integer) : 가격
집계
1. RFM 분석을 위한 3가지 지표로 사용자를 그룹화 하기
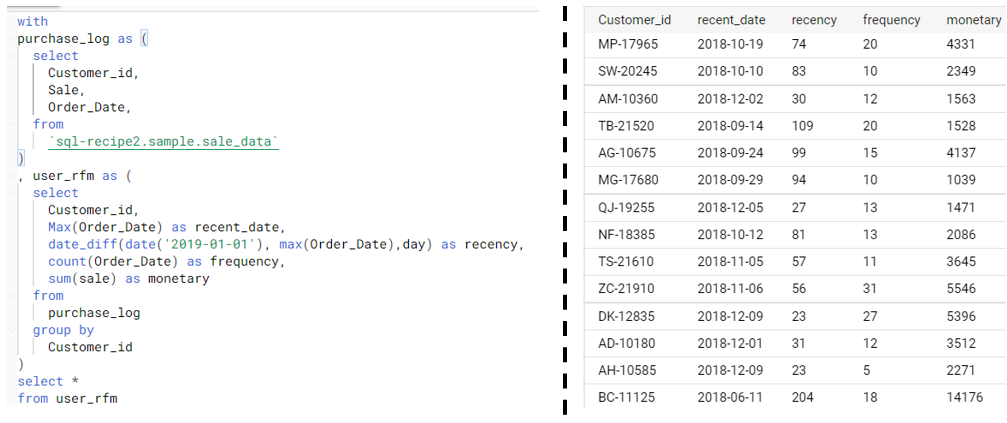
- purchase_log 임시 테이블에서 기존 sample_sale_data 테이블의 Customer_id, Sale, Order_Date 열 추출
- user_rfm 임시 테이블에서 위 purchase_log 테이블의 열을 가공 및 추출
- Customer_id
- Max(Order_Date)로 고객의 가장 최근 구매일을 구함
- Date_diff(date('2019-01-01')), max(Order_Date), day)로 2019-01-01과 최근 구매일의 차를 구함 (작을수록 최근)
- count(Order_Date)로 구매일자의 수를 세어 구매 횟수를 구함
- sum(sale)로 구매 가격의 합을 구함
- Customer_id로 group by 하여 고객 별 집합을 구함
2. RFM 랭크 테이블 정의
| 랭크 | R | F | M |
| 5 | 100일 이내 | 20회 이상 | 5000달러 이상 |
| 4 | 300일 이내 | 13회 이상 | 2000달러 이상 |
| 3 | 600일 이내 | 7회 이상 | 800달러 이상 |
| 2 | 1000일 이내 | 2회 이상 | 300달러 이상 |
| 1 | 1000일 이상 | 1회 이상 | 300달러 미만 |
- R F M 별 기준점을 설정
- 기준점을 바탕으로 랭크를 설정 - 이는 고객군을 나누는 지표가 됨
3. 정의된 랭크 별로 고객 분류

- 1번의 purchase_log, user_rfm 임시 테이블이 생략된 캡처 화면임.
- user_rfm_rank임시 테이블의 생성한 뒤 case 문을 사용하여 정의된 랭크의 쿼리문을 작성
분석
1. 랭킹, (R, F, M) 별 고객 수를 확인

- purchase_log, user_rfm, user_rfm_rank 임시 테이블이 생략된 캡처 화면임.
- mst_rfm_index 임시 테이블을 생성하여 랭킹 열을 만들어 줌
- rfm_flag 임시 테이블의 case 문에서 rfm_index와 r 이 같을 경우 1, 아닐 경우 0을 도출.
- ex) 인덱스 3 = R 랭킹 3 일 경우 1 아닐경우 0
- mst_rfm_index 테이블과 user_rfm_rank 테이블의 cross join
- ex ) 인덱스 1에 user_rfm_rank의 모든 행을 조인, 이하 인덱스에도 같은 방법으로 테이블 생성
- sum(r_flag), sum(f_flag), sum(m_flag)을 통하여 랭킹 별 고객 수 도출
-> R : 100일 이내에 물건을 구입한 고객이 가장 많음
-> F : 7회 이상 구매한 고객이 가장 많음
-> M : 2000달러 이상 구매한 고객이 가장 많음
-> 단, 이 집계는 R, F, M을 따로 보기 때문에, 이것 만으로는 '신규 고객', '우량 고객', '이탈 고객' 등 고객군을 분류할 수 없음.
2. 3차원 그래프를 통한 고객군 분류

- 집계 3의 user_rfm_rank 테이블을 pandas DataFrame화 시킴
- user_rfm_rank의 'R', 'F', 'M' 열을 사용해 3차원 그래프 생성

생성된 그래프를 바탕으로 고객군 분류
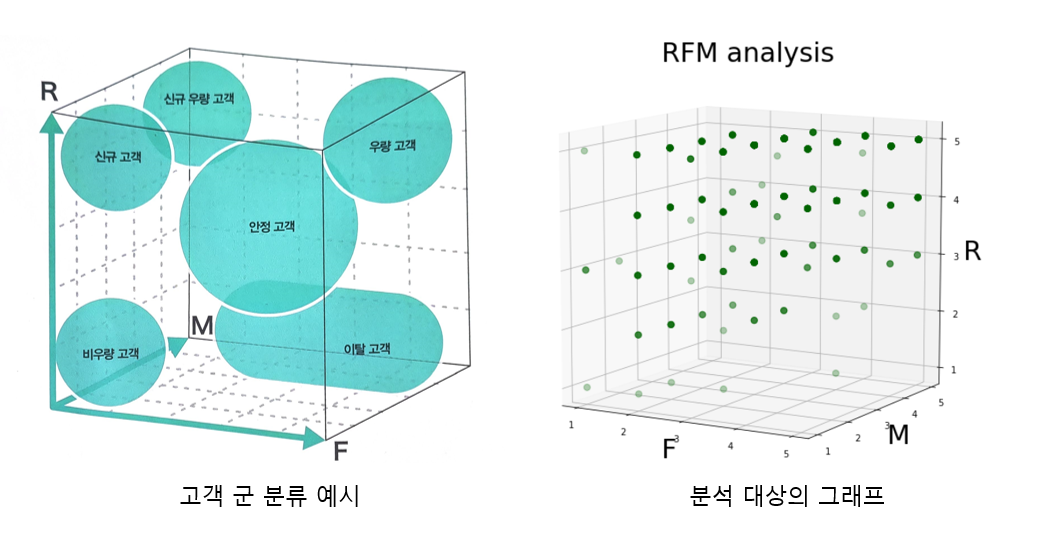
- 3차원 그래프의 고객 군 별 예시를 통해 고객 군 별로 어떤 특성을 가지고 있는지 알 수 있음
- user_rfm_rank 테이블의 'r', 'f', 'm' 열과 3차원 그래프를 비교하여 고객군 분류 예시와 같이 속성별로 고객군을 분류할 수 있음
-> 하지만 최대 125 개의 그룹이 생성되므로 해석 및 관리에 어려움이 생김
3. 사용자를 1차원으로 분류하기

- purchase_log, user_rfm, user_rfm_rank 임시 테이블 생성 후 r + f + m 별 등급을 구함
- 우량 고객(rank : 15, 14, 13)과 비우량 고객(rank : 3,4,5,6)으로 간단히 분류할 수 있음

- 이 집계는 R, F, M을 함께 고려하고, '우량고객'과 '비우량 고객의 수를 알 수 있었음
-> 우량고객 247명, 비우량고객 25명으로 고객 서비스 제공이 잘 되고 있는 것을 알 수 있음
-> 하지만 1차원 분석만으로는 '고객군 별로 어떤 대책을 세워 우량고객으로 만들 수 있을지?'에 대해 세부적인 전략을 세우기 힘듦
4. 2차원 분석
- 'R'과 'F' 열을 사용하여 집계 한 뒤, 각 고객 군을 어떻게 우량 고객으로 만들 수 있을지 대책을 세울 수 있음
- 'R', 'F', 'M' 열의 조합을 통해 많은 고객 군별 대책을 세울 수 있음
- 이번 분석에서는 'R' 과 'F'열을 비교

위 결과를 해석하면 다음과 같음
| 20회 이상 | 10회 이상 | 5회 이상 | 2회 이상 | 1회 이상 | |
| 100일 이내 | 75명 *단골* |
164명 | 172명 | 47명 *신규* |
1명 *신규* |
| 300일 이내 | 22명 | 58명 *안정* |
95명 *안정* |
33명 | 0명 |
| 600일 이내 | 6명 *단골이탈전조* |
14명 *안정이탈전조* |
43명 | 28명 | 4명 |
| 1000일 이내 | 0명 | 2명 | 9명 | 15명 *신규 이탈* |
0명 *신규 이탈* |
| 1000일 이상 | 0명 *단골 이탈* |
1명 *안정 이탈* |
1명 *안정 이탈* |
2명 *신규 이탈* |
1명 *신규 이탈* |
- 단골 : 75명
- 안정 : 153명
- 신규 : 58명
- 이탈 전조 : 20명
- 이탈 : 20명
-> 총 793명 중 75명이 단골 고객으로 단골 고객의 비율이 높음
-> 하지만 단골, 안정 고객 수에 비해 신규 고객의 수가 적음
-> 100일 이내 10회 이상 구매, 5회 이상 구매의 고객 수가 336명으로 가장 많은 고객 수로 나타남
-> 100일 이내 10회, 5회 이상의 고객을 단골 고객으로 유입시킬 시 많은 이윤을 얻을 수 있을 것으로 예상됨
-> 신규 고객 유입을 위한 대책이 시급함
대책
1. 신규 고객 유입을 위한 대책
- 각종 매체, 인플루언서를 통한 광고
- 추천 프로그램 개발
- 검색 엔진 최적화
- 잠재 고객 선정 및 잠재 고객을 위한 마케팅
2. 단골 고객화를 위한 대책
- 구매 후 맞춤형 메시지를 보내 고객과 유대를 지속
- 로열티 프로그램 활용
- 구매를 촉진하기 위해 특별 혜택을 제공
'Specialist > Project' 카테고리의 다른 글
| [디스이즈] 앱 로그 데이터 분석 프로젝트 [3] (0) | 2022.10.08 |
|---|---|
| 모여봐요 동물의 숲 데이터 분석 with BigQuery (3) | 2022.09.18 |
| [디스이즈] 앱 로그 데이터 분석 프로젝트 [2] (0) | 2022.09.03 |
| [디스이즈] 앱 로그 데이터 분석 프로젝트 [1] (0) | 2022.08.29 |
| [디스이즈] 앱 로그 데이터 분석 프로젝트 [시작] (2) | 2022.08.19 |




댓글