최신 글
-
 Excell Skill UP!(3)
들어가며 엑셀 대표 유튜버이신 오빠두엑셀님께서 진행하시는 엑셀 스터디의 마지막 공부 내용을 정리한 글입니다. (공개 가능합니다.) 사소하게 시간을 많이 잡아먹던 작업을 한방에 해결하는 유용한 꿀팁이 많으니, 글을 읽으시는 분들께 도움이 되었으면 좋겠습니다. 엑셀강의 대표채널! 오빠두엑셀 - 오빠두엑셀 1980년 ~ 2040년 까지 양력/음력 날짜 데이터가 포함된 엑셀 양력 음력 변환표입니다. (음력간지, 율리우스적일 포함) ⭐️ 모든 일반 회원에게 무료로 제공되는 자료입니다. www.oppadu.com 1. 데이터 시각화 시각화의 핵심 요소 데이터는 내림차순으로 정렬 스파크라인과 차트를 적극 활용하여 한눈에 파악하도록 표시 전달하고자 하는 주요 메세지를 선정 천단위 기호 표시 필수 월별 합계 추가 시각화..
2023.03.28
Excell Skill UP!(3)
들어가며 엑셀 대표 유튜버이신 오빠두엑셀님께서 진행하시는 엑셀 스터디의 마지막 공부 내용을 정리한 글입니다. (공개 가능합니다.) 사소하게 시간을 많이 잡아먹던 작업을 한방에 해결하는 유용한 꿀팁이 많으니, 글을 읽으시는 분들께 도움이 되었으면 좋겠습니다. 엑셀강의 대표채널! 오빠두엑셀 - 오빠두엑셀 1980년 ~ 2040년 까지 양력/음력 날짜 데이터가 포함된 엑셀 양력 음력 변환표입니다. (음력간지, 율리우스적일 포함) ⭐️ 모든 일반 회원에게 무료로 제공되는 자료입니다. www.oppadu.com 1. 데이터 시각화 시각화의 핵심 요소 데이터는 내림차순으로 정렬 스파크라인과 차트를 적극 활용하여 한눈에 파악하도록 표시 전달하고자 하는 주요 메세지를 선정 천단위 기호 표시 필수 월별 합계 추가 시각화..
2023.03.28
-
 Excell Skill UP!(2)
들어가며 엑셀 대표 유튜버이신 오빠두엑셀님께서 진행하시는 엑셀 스터디의 두 번째 공부 내용을 정리한 글입니다. (공개 가능합니다.) 사소하게 시간을 많이 잡아먹던 작업을 한방에 해결하는 유용한 꿀팁이 많으니, 글을 읽으시는 분들께 도움이 되었으면 좋겠습니다. 엑셀강의 대표채널! 오빠두엑셀 - 오빠두엑셀 1980년 ~ 2040년 까지 양력/음력 날짜 데이터가 포함된 엑셀 양력 음력 변환표입니다. (음력간지, 율리우스적일 포함) ⭐️ 모든 일반 회원에게 무료로 제공되는 자료입니다. www.oppadu.com 1. 자동 확장 목록상자 만들기 문제 상황 원가표에 새 제품명 추가 시, 기존 목록 상자에는 추가되지 않는 문제 상황 발생 해결 방법 (1) 표 생성 - 기존 원가표(셀)를 표로 만들기 단축키 : Ctr..
2023.03.19
Excell Skill UP!(2)
들어가며 엑셀 대표 유튜버이신 오빠두엑셀님께서 진행하시는 엑셀 스터디의 두 번째 공부 내용을 정리한 글입니다. (공개 가능합니다.) 사소하게 시간을 많이 잡아먹던 작업을 한방에 해결하는 유용한 꿀팁이 많으니, 글을 읽으시는 분들께 도움이 되었으면 좋겠습니다. 엑셀강의 대표채널! 오빠두엑셀 - 오빠두엑셀 1980년 ~ 2040년 까지 양력/음력 날짜 데이터가 포함된 엑셀 양력 음력 변환표입니다. (음력간지, 율리우스적일 포함) ⭐️ 모든 일반 회원에게 무료로 제공되는 자료입니다. www.oppadu.com 1. 자동 확장 목록상자 만들기 문제 상황 원가표에 새 제품명 추가 시, 기존 목록 상자에는 추가되지 않는 문제 상황 발생 해결 방법 (1) 표 생성 - 기존 원가표(셀)를 표로 만들기 단축키 : Ctr..
2023.03.19
-
 Excel Skill UP!(1)
들어가며 엑셀 대표 유튜버이신 오빠두엑셀님께서 스터디를 3주간 진행한다는 소식을 듣고 얼른 신청하였습니다. 첫 번째 스터디의 공부 내용을 정리한 글입니다. (공개 가능합니다.) 사소하게 시간을 많이 잡아먹던 작업을 한방에 해결하는 유용한 꿀팁이 많으니, 글을 읽으시는 분들께 도움이 되었으면 좋겠습니다. 엑셀강의 대표채널! 오빠두엑셀 - 오빠두엑셀 1980년 ~ 2040년 까지 양력/음력 날짜 데이터가 포함된 엑셀 양력 음력 변환표입니다. (음력간지, 율리우스적일 포함) ⭐️ 모든 일반 회원에게 무료로 제공되는 자료입니다. www.oppadu.com 1. 빠른 채우기 기존 데이터 값의 패턴을 분석하여 데이터 값을 빠르게 채우는 기능 단축키 : Ctrl + E 2. 빠른 테두리 설정 테두리 설정 단축키 단축..
2023.03.16
Excel Skill UP!(1)
들어가며 엑셀 대표 유튜버이신 오빠두엑셀님께서 스터디를 3주간 진행한다는 소식을 듣고 얼른 신청하였습니다. 첫 번째 스터디의 공부 내용을 정리한 글입니다. (공개 가능합니다.) 사소하게 시간을 많이 잡아먹던 작업을 한방에 해결하는 유용한 꿀팁이 많으니, 글을 읽으시는 분들께 도움이 되었으면 좋겠습니다. 엑셀강의 대표채널! 오빠두엑셀 - 오빠두엑셀 1980년 ~ 2040년 까지 양력/음력 날짜 데이터가 포함된 엑셀 양력 음력 변환표입니다. (음력간지, 율리우스적일 포함) ⭐️ 모든 일반 회원에게 무료로 제공되는 자료입니다. www.oppadu.com 1. 빠른 채우기 기존 데이터 값의 패턴을 분석하여 데이터 값을 빠르게 채우는 기능 단축키 : Ctrl + E 2. 빠른 테두리 설정 테두리 설정 단축키 단축..
2023.03.16
-
 구글 옵티마이즈를 이용한 A/B test (feat.맞춤 Click 이벤트 생성)
0. 들어가며 길었던 대학 생활의 마지막 수업에, 그동안 작성한 GA 관련 글을 1시간가량 발표하는 영광스러운 기회가 있었습니다. 학생들은 제 블로그를 자유롭게 살펴보고, 저는 5개의 블로그 글을 간단히 설명만 해주면 되는 발표였습니다. 발표를 준비하던 중 문득 '학생들이 제 블로그를 살펴볼 때 몰래 A/B 테스트를 진행하고, 소개하면 재밌겠는데..?'라는 생각이 들었고, 얼른 준비해 보았습니다. 이 글의 목적은 [실험 결과의 공유]가 아니라, 발표 때 자세히 설명드리지 못했던 [실험을 구성하는 방법]의 공유입니다. 많은 분들이 이 글로 A/B test 를 쉽게 세팅했으면 합니다. 글 내용 1. 맞춤 목표 설정 - 구글 태그 매니저 (태그매니저가 설치되어 있어야 합니다.) 2. A/B 테스트 세팅 - 구..
2022.12.15
구글 옵티마이즈를 이용한 A/B test (feat.맞춤 Click 이벤트 생성)
0. 들어가며 길었던 대학 생활의 마지막 수업에, 그동안 작성한 GA 관련 글을 1시간가량 발표하는 영광스러운 기회가 있었습니다. 학생들은 제 블로그를 자유롭게 살펴보고, 저는 5개의 블로그 글을 간단히 설명만 해주면 되는 발표였습니다. 발표를 준비하던 중 문득 '학생들이 제 블로그를 살펴볼 때 몰래 A/B 테스트를 진행하고, 소개하면 재밌겠는데..?'라는 생각이 들었고, 얼른 준비해 보았습니다. 이 글의 목적은 [실험 결과의 공유]가 아니라, 발표 때 자세히 설명드리지 못했던 [실험을 구성하는 방법]의 공유입니다. 많은 분들이 이 글로 A/B test 를 쉽게 세팅했으면 합니다. 글 내용 1. 맞춤 목표 설정 - 구글 태그 매니저 (태그매니저가 설치되어 있어야 합니다.) 2. A/B 테스트 세팅 - 구..
2022.12.15
-
 가짜뉴스 분류 모델(RNN, LSTM, GRU, CNN-LSTM)
0. 들어가며 학교 수업에서 조별로 주제를 정해 딥러닝 모델을 만들고, 발표를 하는 기회가 있었습니다. 이번 글은 제가 했던 발표를 남기기 위해 작성하는 글입니다. 발표 대본 초안을 옮겨놓은 글이므로 다소 정제되지 않았을 수 있고, 발표 대상이 대부분 데이터 사이언스 초보이었기에 자세한 내용보다는 모델링 과정을 최대한 쉽게 설명을 했습니다. 1. 데이터 소개 저희가 맞은 주제는 가짜뉴스 분류 모델입니다. 그럼 발표를 시작하겠습니다. 여기 두가지 기사가 있습니다. ‘예일 대학교는 칼훈 칼리지의 이름을 바꿀 수 있는 정책을 수립했다.’ ,‘ 텔레비전은 아이들의 발달에 부정적인 영향을 끼친다.’ 어떤것 진짜 뉴스이고, 가짜 뉴스인 것 같나요? 실제로 미국을 대표하는 사립학교인 예일대 산하 학부인 칼훈 칼리지는..
2022.12.11
가짜뉴스 분류 모델(RNN, LSTM, GRU, CNN-LSTM)
0. 들어가며 학교 수업에서 조별로 주제를 정해 딥러닝 모델을 만들고, 발표를 하는 기회가 있었습니다. 이번 글은 제가 했던 발표를 남기기 위해 작성하는 글입니다. 발표 대본 초안을 옮겨놓은 글이므로 다소 정제되지 않았을 수 있고, 발표 대상이 대부분 데이터 사이언스 초보이었기에 자세한 내용보다는 모델링 과정을 최대한 쉽게 설명을 했습니다. 1. 데이터 소개 저희가 맞은 주제는 가짜뉴스 분류 모델입니다. 그럼 발표를 시작하겠습니다. 여기 두가지 기사가 있습니다. ‘예일 대학교는 칼훈 칼리지의 이름을 바꿀 수 있는 정책을 수립했다.’ ,‘ 텔레비전은 아이들의 발달에 부정적인 영향을 끼친다.’ 어떤것 진짜 뉴스이고, 가짜 뉴스인 것 같나요? 실제로 미국을 대표하는 사립학교인 예일대 산하 학부인 칼훈 칼리지는..
2022.12.11
-
 BigQuery로 분석한 Hongwon's Data 블로그 [2]
※0. 들어가며 1편에선 5일간 블로그 사용자의 로그 데이터로 분석을 해보았습니다. 이번 글에선 10월 9일 ~ 11월 12일까지 35일간의 로그 데이터로 여러 분석을 진행해보겠습니다. 분석 주제 접근 요일과 시간대 알아보기 페이지 완독률 알아보기 성장 지수 ※ 중요: 본문에는 분석 코드를 생략했습니다. 코드를 보시려면 글 하단의 깃허브 링크에서 확인해주세요! 1. 데이터 개요 BigQuery로 분석한 Hongwon's Data 블로그 [1] 0. 들어가며 GA 분석 내용이 아닌 더 높은 레벨의 분석을 위해서 로우 데이터 분석이 필수적입니다. GA4는 Bigquery와 무료로 연동하여 로우 데이터를 받아볼 수 있습니다. 이번 글에선 SQL로 직접 제 khw742002.tistory.com 10월9일 ~ ..
2022.11.16
BigQuery로 분석한 Hongwon's Data 블로그 [2]
※0. 들어가며 1편에선 5일간 블로그 사용자의 로그 데이터로 분석을 해보았습니다. 이번 글에선 10월 9일 ~ 11월 12일까지 35일간의 로그 데이터로 여러 분석을 진행해보겠습니다. 분석 주제 접근 요일과 시간대 알아보기 페이지 완독률 알아보기 성장 지수 ※ 중요: 본문에는 분석 코드를 생략했습니다. 코드를 보시려면 글 하단의 깃허브 링크에서 확인해주세요! 1. 데이터 개요 BigQuery로 분석한 Hongwon's Data 블로그 [1] 0. 들어가며 GA 분석 내용이 아닌 더 높은 레벨의 분석을 위해서 로우 데이터 분석이 필수적입니다. GA4는 Bigquery와 무료로 연동하여 로우 데이터를 받아볼 수 있습니다. 이번 글에선 SQL로 직접 제 khw742002.tistory.com 10월9일 ~ ..
2022.11.16
-
 BigQuery - Colab 연동법 (ver. 최신 업데이트)
원래 bigquery와 colab을 연동하기 위해서는 꽤 복잡한 방법을 거쳐야 했습니다. 빅쿼리와 코랩을 넘나드는 자유로운 분석, 시각화에 불편함은 물론이고, 그 분석 내용을 notebook 형태로 정리하기 위해서는 정말 많은 시간이 소요되었습니다. 그러던 2022년 10월 21일 Google Cloud Blog에 Build limitless workloads on BigQuery: New features beyond SQL란 글이 업로드되었습니다. BigQuery removes SQL-only limits and provides new developer extensions | Google Cloud Blog BigQuery announces preview of Stored Procedures for S..
2022.10.26
BigQuery - Colab 연동법 (ver. 최신 업데이트)
원래 bigquery와 colab을 연동하기 위해서는 꽤 복잡한 방법을 거쳐야 했습니다. 빅쿼리와 코랩을 넘나드는 자유로운 분석, 시각화에 불편함은 물론이고, 그 분석 내용을 notebook 형태로 정리하기 위해서는 정말 많은 시간이 소요되었습니다. 그러던 2022년 10월 21일 Google Cloud Blog에 Build limitless workloads on BigQuery: New features beyond SQL란 글이 업로드되었습니다. BigQuery removes SQL-only limits and provides new developer extensions | Google Cloud Blog BigQuery announces preview of Stored Procedures for S..
2022.10.26
-
 BigQuery로 분석한 Hongwon's Data 블로그 [1]
0. 들어가며 GA 분석 내용이 아닌 더 높은 레벨의 분석을 위해서 로우 데이터 분석이 필수적입니다. GA4는 Bigquery와 무료로 연동하여 로우 데이터를 받아볼 수 있습니다. 이번 글에선 SQL로 직접 제 블로그 사용자의 로우 데이터를 분석해보겠습니다. 분석 주제 날짜별 사용자 수 대비 첫 사용자 비율은? 최다 조회 사용자의 특성은? 외국에서 접속한 사용자가 본 페이지는? ※ 참고 GA4와 Bigquery의 연동방법 강의자료 - GA4 - 빅쿼리(BigQuery) 연결하는 방법 GA4 - 빅쿼리(BigQuery) 연결 2가지 단계로 나뉩니다. 복잡한 내용이 아니므로 천천히 진행 하시면 됩니다. ---- STEP1 . 빅쿼리 개설 및 프로젝트 생성 STEP2 . 생성된 빅쿼리 프로젝트 - GA4 연결..
2022.10.15
BigQuery로 분석한 Hongwon's Data 블로그 [1]
0. 들어가며 GA 분석 내용이 아닌 더 높은 레벨의 분석을 위해서 로우 데이터 분석이 필수적입니다. GA4는 Bigquery와 무료로 연동하여 로우 데이터를 받아볼 수 있습니다. 이번 글에선 SQL로 직접 제 블로그 사용자의 로우 데이터를 분석해보겠습니다. 분석 주제 날짜별 사용자 수 대비 첫 사용자 비율은? 최다 조회 사용자의 특성은? 외국에서 접속한 사용자가 본 페이지는? ※ 참고 GA4와 Bigquery의 연동방법 강의자료 - GA4 - 빅쿼리(BigQuery) 연결하는 방법 GA4 - 빅쿼리(BigQuery) 연결 2가지 단계로 나뉩니다. 복잡한 내용이 아니므로 천천히 진행 하시면 됩니다. ---- STEP1 . 빅쿼리 개설 및 프로젝트 생성 STEP2 . 생성된 빅쿼리 프로젝트 - GA4 연결..
2022.10.15
-
 [디스이즈] 앱 로그 데이터 분석 프로젝트 [3]
이전 과정 [디스이즈] 앱 로그 데이터 분석 프로젝트 [2] 이전 과정 [디스이즈] 앱 로그 데이터 분석 프로젝트 [1] 이전 과정 [디스이즈] 앱 사용자 데이터 분석 프로젝트 [시작] 1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아 khw742002.tistory.com 1차 로그 설계 추가 회의 문제 해결 최종 로그 설계 1. 리뷰 텍스트 데이터 분석 (1) 리뷰 크롤링 개요 개발 팀이 충분한 공부 시간을 가지고 정확한 로그 개발을 하는 것을 대기하며, 과거부터 현재까지의 디스이즈가 사용자에게 어떤 경험을 주었을지 알아보기 위해 앱 리뷰 텍스트 분석을 진행하였습니다. 크롤링 도구 : UI Path 크롤링 내용 : 플레이 스토어 - 디스이즈 리뷰 크롤링 프로세스 Flow cha..
2022.10.08
[디스이즈] 앱 로그 데이터 분석 프로젝트 [3]
이전 과정 [디스이즈] 앱 로그 데이터 분석 프로젝트 [2] 이전 과정 [디스이즈] 앱 로그 데이터 분석 프로젝트 [1] 이전 과정 [디스이즈] 앱 사용자 데이터 분석 프로젝트 [시작] 1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아 khw742002.tistory.com 1차 로그 설계 추가 회의 문제 해결 최종 로그 설계 1. 리뷰 텍스트 데이터 분석 (1) 리뷰 크롤링 개요 개발 팀이 충분한 공부 시간을 가지고 정확한 로그 개발을 하는 것을 대기하며, 과거부터 현재까지의 디스이즈가 사용자에게 어떤 경험을 주었을지 알아보기 위해 앱 리뷰 텍스트 분석을 진행하였습니다. 크롤링 도구 : UI Path 크롤링 내용 : 플레이 스토어 - 디스이즈 리뷰 크롤링 프로세스 Flow cha..
2022.10.08
-
 GA4 정복하기 [3] - 탐색 보고서로 분석한 Hongwon's Data 블로그
0. 들어가며 이전 글 의 '최다 조회수를 기록한 페이지'의 분석 결과는 '1편을 본 사용자가 대부분 2편으로 넘어갔을 것이다.'였습니다. 이번 글에서는 GA4의 탐색 보고서로 정말 사용자가 '1편'에서 '2편'으로 이동했을지 알아보겠습니다. 좌측 바의 '탐색' 에 접속하여 '비어있음'을 클릭하여 새 탐색 보고서를 만들어주세요. 탐색 분석 보고서의 첫번째 화면입니다. 좌측 바를 조정하여 분석해보겠습니다. 1. 경로 탐색 분석 탐색 보고서의 경로 탐색 분석 기법을 사용하여 유저들이 발생시키는 이벤트의 흐름을 알아보겠습니다. ① 기법 - '경로 탐색 분석'을 선택합니다. 제 블로그에 접속한 사용자는 'session_start' → 'page_view' → 'scroll'의 이벤트를 진행했습니다. 글 페이지에..
2022.10.05
GA4 정복하기 [3] - 탐색 보고서로 분석한 Hongwon's Data 블로그
0. 들어가며 이전 글 의 '최다 조회수를 기록한 페이지'의 분석 결과는 '1편을 본 사용자가 대부분 2편으로 넘어갔을 것이다.'였습니다. 이번 글에서는 GA4의 탐색 보고서로 정말 사용자가 '1편'에서 '2편'으로 이동했을지 알아보겠습니다. 좌측 바의 '탐색' 에 접속하여 '비어있음'을 클릭하여 새 탐색 보고서를 만들어주세요. 탐색 분석 보고서의 첫번째 화면입니다. 좌측 바를 조정하여 분석해보겠습니다. 1. 경로 탐색 분석 탐색 보고서의 경로 탐색 분석 기법을 사용하여 유저들이 발생시키는 이벤트의 흐름을 알아보겠습니다. ① 기법 - '경로 탐색 분석'을 선택합니다. 제 블로그에 접속한 사용자는 'session_start' → 'page_view' → 'scroll'의 이벤트를 진행했습니다. 글 페이지에..
2022.10.05
-
 GA4 정복하기 [2] - 기본 보고서로 분석한 Hongwon's Data 블로그
0. 들어가며 이전 글에서는 GA와 GA4가 무엇인지 알아보았습니다. 이번 글에서는 GA4 기본 분석 보고서를 활용하여 제 블로그의 사용자 데이터 분석을 하였습니다. (GA의 설치 방법은 다루지 않습니다.) 1. GA4 보고서 카테고리 위 사진은 제 블로그에 GA4를 설치 한 뒤, GA에 접속하면 보게 되는 첫 페이지(홈 카테고리)입니다. '홈 카테고리'는 '보고서 카테고리'의 요약본입니다. 저는 '보고서 카테고리'에 접속하여 GA4가 분석한 내용을 자세히 알아보겠습니다. 그리고 사실 '홈' 카테고리는 다음 단락의 '보고서' - 보고서 개요' 카테고리와 같은 내용이니, 이번 글에서 '홈' 카테고리 설명은 생략하겠습니다. 그럼, '보고서' 카테고리에 접속해보겠습니다. 2. '보고서'의 소 카테고리 '보고서..
2022.10.03
GA4 정복하기 [2] - 기본 보고서로 분석한 Hongwon's Data 블로그
0. 들어가며 이전 글에서는 GA와 GA4가 무엇인지 알아보았습니다. 이번 글에서는 GA4 기본 분석 보고서를 활용하여 제 블로그의 사용자 데이터 분석을 하였습니다. (GA의 설치 방법은 다루지 않습니다.) 1. GA4 보고서 카테고리 위 사진은 제 블로그에 GA4를 설치 한 뒤, GA에 접속하면 보게 되는 첫 페이지(홈 카테고리)입니다. '홈 카테고리'는 '보고서 카테고리'의 요약본입니다. 저는 '보고서 카테고리'에 접속하여 GA4가 분석한 내용을 자세히 알아보겠습니다. 그리고 사실 '홈' 카테고리는 다음 단락의 '보고서' - 보고서 개요' 카테고리와 같은 내용이니, 이번 글에서 '홈' 카테고리 설명은 생략하겠습니다. 그럼, '보고서' 카테고리에 접속해보겠습니다. 2. '보고서'의 소 카테고리 '보고서..
2022.10.03
-
 GA4 정복하기 [1] - GA4란 무엇인가?
GA4를 알아보기 앞서, GA란? Google Analytics는 Google에서 무료로 제공하는 웹 로그 분석 툴입니다. Google Analytics를 웹사이트에 설치하여 방문자의 유입 소스나 사이트 내 행동과 같은 유용한 정보를 자동으로 수집하고 저장, 분석할 수 있습니다. GA의 역사 구글 애널리틱스는 2005년 'Urchin'이란 서비스로 시작했습니다. 이를 GA1이라 칭합니다. 이후 GA2를 거쳐 GA3 - universal Analytics 서비스가 '웹 로그 분석'을 무기로 지금까지 활용되고 있습니다. 하지만 2020년 구글은 2023년 7월까지 모든 GA3을 GA4로 전환시키겠다는 발표를 하였습니다. 그럼 GA4가 도대체 무엇이기에, 구글은 그러한 전환 계획을 가지고 있을까요? GA4의 ..
2022.09.28
GA4 정복하기 [1] - GA4란 무엇인가?
GA4를 알아보기 앞서, GA란? Google Analytics는 Google에서 무료로 제공하는 웹 로그 분석 툴입니다. Google Analytics를 웹사이트에 설치하여 방문자의 유입 소스나 사이트 내 행동과 같은 유용한 정보를 자동으로 수집하고 저장, 분석할 수 있습니다. GA의 역사 구글 애널리틱스는 2005년 'Urchin'이란 서비스로 시작했습니다. 이를 GA1이라 칭합니다. 이후 GA2를 거쳐 GA3 - universal Analytics 서비스가 '웹 로그 분석'을 무기로 지금까지 활용되고 있습니다. 하지만 2020년 구글은 2023년 7월까지 모든 GA3을 GA4로 전환시키겠다는 발표를 하였습니다. 그럼 GA4가 도대체 무엇이기에, 구글은 그러한 전환 계획을 가지고 있을까요? GA4의 ..
2022.09.28
-
 Kaggle 데이터를 Google Cloud Storage로 이동시키기
데이터 분석 공부를 위해 많은 데이터 셋들을 kaggle 에서 다운받던 중, 제 노트북에 용량 압박이 점점 느껴졌습니다. 주로 GCP를 사용하는 제 환경 상 Google Cloud Storage (이하 GCS)에 kaggle 데이터를 바로 저장하는것이 효과적이었습니다. 이번 글에서는 Kaggle 데이터를 GCS로 이동시키는 방법을 알아보겠습니다. 1. 새 Kaggle 노트북 생성 캐글 홈페이지에서 왼쪽 상단의 Create - New Notebook 을 클릭하여 새 캐글 노트북을 생성합니다. 2. 데이터 셋 추가 생성된 노트북의 우측 바 - Add Data를 클릭하여 자신이 필요한 캐글 데이터 셋을 추가합니다. 저는 이전 분석에 사용한 동물의 숲 데이터를 가져오겠습니다. 3. 데이터를 GCS로 이동시키기 ..
2022.09.23
Kaggle 데이터를 Google Cloud Storage로 이동시키기
데이터 분석 공부를 위해 많은 데이터 셋들을 kaggle 에서 다운받던 중, 제 노트북에 용량 압박이 점점 느껴졌습니다. 주로 GCP를 사용하는 제 환경 상 Google Cloud Storage (이하 GCS)에 kaggle 데이터를 바로 저장하는것이 효과적이었습니다. 이번 글에서는 Kaggle 데이터를 GCS로 이동시키는 방법을 알아보겠습니다. 1. 새 Kaggle 노트북 생성 캐글 홈페이지에서 왼쪽 상단의 Create - New Notebook 을 클릭하여 새 캐글 노트북을 생성합니다. 2. 데이터 셋 추가 생성된 노트북의 우측 바 - Add Data를 클릭하여 자신이 필요한 캐글 데이터 셋을 추가합니다. 저는 이전 분석에 사용한 동물의 숲 데이터를 가져오겠습니다. 3. 데이터를 GCS로 이동시키기 ..
2022.09.23
-
 모여봐요 동물의 숲 데이터 분석 with BigQuery
매일 자기 전 30분 정도 '동물의 숲' 이란 게임을 하는 것이 제 오랜 루틴 중 하나입니다. 동물의 숲은 닌텐도 사의 게임으로, 최신버전인 '모여봐요 동물의 숲'은 무인도에 주민 동물들과 함께 섬을 개척하는 게임입니다. 무인도의 유유자적한 생활을 즐기고, 동물들과 대화하는 것이 게임의 전부이지만, 그 점을 저는 정말 좋아합니다. 오늘은 가벼운 마음으로 동물의숲 데이터를 활용한 데이터 분석을 해보겠습니다. 모여봐요 동물의 숲 데이터 분석 with bigquery 동물의 숲에는 여러 동물 주민들이 있습니다. 동물들은 각자 특성이 달라서, 플레이어들이 보편적으로 좋아하는 동물, 잠자리채로 쫓아내 버리고 싶은 동물들이 있습니다. 이번 분석에서는 빅쿼리를 활용하여 유저들이 어떤 동물들의 특성을 선호하고 있는지 ..
2022.09.18
모여봐요 동물의 숲 데이터 분석 with BigQuery
매일 자기 전 30분 정도 '동물의 숲' 이란 게임을 하는 것이 제 오랜 루틴 중 하나입니다. 동물의 숲은 닌텐도 사의 게임으로, 최신버전인 '모여봐요 동물의 숲'은 무인도에 주민 동물들과 함께 섬을 개척하는 게임입니다. 무인도의 유유자적한 생활을 즐기고, 동물들과 대화하는 것이 게임의 전부이지만, 그 점을 저는 정말 좋아합니다. 오늘은 가벼운 마음으로 동물의숲 데이터를 활용한 데이터 분석을 해보겠습니다. 모여봐요 동물의 숲 데이터 분석 with bigquery 동물의 숲에는 여러 동물 주민들이 있습니다. 동물들은 각자 특성이 달라서, 플레이어들이 보편적으로 좋아하는 동물, 잠자리채로 쫓아내 버리고 싶은 동물들이 있습니다. 이번 분석에서는 빅쿼리를 활용하여 유저들이 어떤 동물들의 특성을 선호하고 있는지 ..
2022.09.18
-
 [디스이즈] 앱 로그 데이터 분석 프로젝트 [2]
이전 과정 [디스이즈] 앱 로그 데이터 분석 프로젝트 [1] 이전 과정 [디스이즈] 앱 사용자 데이터 분석 프로젝트 [시작] 1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아대학교 스마트 캠퍼스' 애플리케이션입니다. 학사일정, khw742002.tistory.com 디스이즈 앱 UI 설명 정보구조도 작성 로그 설계의 목적 및 지표 설정 1. 1차 로그 설계 이전 글의 필요 로그에 이벤트 로그는 기능별 클릭 로그였습니다.따라서 앱의 각 기능 별로 클릭 로그를 설계했습니다. 그리고 필요 로그 중 유저 로그는 앱에 로그인 기능이 있었으므로 user_id 로그를 설계하여 접속한 유저가 누구인지 특정하기로 했습니다. 1차적으로 저희가 설계한 로그의 예시는 아래와 같았습니다. {“user_i..
2022.09.03
[디스이즈] 앱 로그 데이터 분석 프로젝트 [2]
이전 과정 [디스이즈] 앱 로그 데이터 분석 프로젝트 [1] 이전 과정 [디스이즈] 앱 사용자 데이터 분석 프로젝트 [시작] 1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아대학교 스마트 캠퍼스' 애플리케이션입니다. 학사일정, khw742002.tistory.com 디스이즈 앱 UI 설명 정보구조도 작성 로그 설계의 목적 및 지표 설정 1. 1차 로그 설계 이전 글의 필요 로그에 이벤트 로그는 기능별 클릭 로그였습니다.따라서 앱의 각 기능 별로 클릭 로그를 설계했습니다. 그리고 필요 로그 중 유저 로그는 앱에 로그인 기능이 있었으므로 user_id 로그를 설계하여 접속한 유저가 누구인지 특정하기로 했습니다. 1차적으로 저희가 설계한 로그의 예시는 아래와 같았습니다. {“user_i..
2022.09.03
-
 [디스이즈] 앱 로그 데이터 분석 프로젝트 [1]
이전 과정 [디스이즈] 앱 사용자 데이터 분석 프로젝트 [시작] 1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아대학교 스마트 캠퍼스' 애플리케이션입니다. 학사일정, 학사공지, 교내식당메뉴, 순환버스, 도서관 좌석 수 등 학생들 khw742002.tistory.com 프로젝트 시작 이유 설명 1. 디스이즈 앱 UI 본격적인 프로젝트에 들어가기 앞서, 독자의 이해를 위해 디스이즈 앱을 간단히 알아보겠습니다. 디스이즈 앱은 위 사진과 같습니다. 각 페이지에는 학생들이 학교생활을 하며 필요한 정보를 알려주는 기능이 있습니다. '디스스탑이즈' 기능은 학교 캠퍼스 간 이동을 위한 셔틀버스의 현 위치를 알려주는 기능입니다. 2. 정보구조도 작성 디스이즈 앱은 컴퓨터 공학과의 개발 공부를 위한..
2022.08.29
[디스이즈] 앱 로그 데이터 분석 프로젝트 [1]
이전 과정 [디스이즈] 앱 사용자 데이터 분석 프로젝트 [시작] 1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아대학교 스마트 캠퍼스' 애플리케이션입니다. 학사일정, 학사공지, 교내식당메뉴, 순환버스, 도서관 좌석 수 등 학생들 khw742002.tistory.com 프로젝트 시작 이유 설명 1. 디스이즈 앱 UI 본격적인 프로젝트에 들어가기 앞서, 독자의 이해를 위해 디스이즈 앱을 간단히 알아보겠습니다. 디스이즈 앱은 위 사진과 같습니다. 각 페이지에는 학생들이 학교생활을 하며 필요한 정보를 알려주는 기능이 있습니다. '디스스탑이즈' 기능은 학교 캠퍼스 간 이동을 위한 셔틀버스의 현 위치를 알려주는 기능입니다. 2. 정보구조도 작성 디스이즈 앱은 컴퓨터 공학과의 개발 공부를 위한..
2022.08.29
-
 [디스이즈] 앱 로그 데이터 분석 프로젝트 [시작]
1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아대학교 스마트 캠퍼스' 애플리케이션입니다. 학사일정, 학사공지, 교내식당메뉴, 순환버스, 도서관 좌석 수 등 학생들이 학교 생활에서 필요한 정보를 보여주는 기능이 있습니다. 구글 플레이스토어/앱스토어 첫 배포 이후 현재까지 1만 이상의 다운로드 수를 기록하며, 학생들의 학교생활을 도와주고 있습니다. 2. 현상황 2019년 코로나 바이러스의 확산으로 인해 학교 생활의 비중이 줄어들고, 재학생 간의 입소문의 부재로 디스이즈 앱의 명성이 줄어들어 사용자 수가 줄어들고 있습니다. 그리고 앱 리뉴얼 개발 이후 로그 개발이 되어있지 않아, 앱 사용자의 행동이 기록되지 않고 있었습니다. 3. 디스이즈 앱 사용자 분석 프로젝트 저를 포함한 4명이 ..
2022.08.19
[디스이즈] 앱 로그 데이터 분석 프로젝트 [시작]
1. 디스이즈란? 디스이즈는 동아대학교 컴퓨터공학과 개발팀이 만든 '동아대학교 스마트 캠퍼스' 애플리케이션입니다. 학사일정, 학사공지, 교내식당메뉴, 순환버스, 도서관 좌석 수 등 학생들이 학교 생활에서 필요한 정보를 보여주는 기능이 있습니다. 구글 플레이스토어/앱스토어 첫 배포 이후 현재까지 1만 이상의 다운로드 수를 기록하며, 학생들의 학교생활을 도와주고 있습니다. 2. 현상황 2019년 코로나 바이러스의 확산으로 인해 학교 생활의 비중이 줄어들고, 재학생 간의 입소문의 부재로 디스이즈 앱의 명성이 줄어들어 사용자 수가 줄어들고 있습니다. 그리고 앱 리뉴얼 개발 이후 로그 개발이 되어있지 않아, 앱 사용자의 행동이 기록되지 않고 있었습니다. 3. 디스이즈 앱 사용자 분석 프로젝트 저를 포함한 4명이 ..
2022.08.19
-
 에이블리(ABLY)의 "샥-출발" - AARRR 분석
이전 글에서 AARRR에 대해 알아보았다. 이번 글에서는 '에이블리의 샥-출발' 서비스를 AARRR 방법론을 기준을 분석해보며 실습해보았다. AARRR이란? 1. 지표란? AARRR을 알아보기에 앞서, 지표 (metric)가 무엇인지 알아야 한다. 지표란 로그를 특정 기준에 따라서 요약한 숫자를 말한다. ex) 클릭 수 , 채택률, 문의 수 기존 업무에서 지표를 관리하는 khw742002.tistory.com 에이블리 샥-출발 알아보기 분석에 앞서 에이블리는 어떤 기업인지, 에이블리의 샥-출발은 어떤 서비스인지 알아보겠다. 1) 에이블리 에이블리는 온라인 동영상 서비스(OTT) ‘왓챠’의 공동 창업자 출신인 강석훈 대표가 세운 여성 패션 플랫폼이다. 출시 후 3년여 만에 누적 거래액 1조원, 누적 다운로..
2022.08.19
에이블리(ABLY)의 "샥-출발" - AARRR 분석
이전 글에서 AARRR에 대해 알아보았다. 이번 글에서는 '에이블리의 샥-출발' 서비스를 AARRR 방법론을 기준을 분석해보며 실습해보았다. AARRR이란? 1. 지표란? AARRR을 알아보기에 앞서, 지표 (metric)가 무엇인지 알아야 한다. 지표란 로그를 특정 기준에 따라서 요약한 숫자를 말한다. ex) 클릭 수 , 채택률, 문의 수 기존 업무에서 지표를 관리하는 khw742002.tistory.com 에이블리 샥-출발 알아보기 분석에 앞서 에이블리는 어떤 기업인지, 에이블리의 샥-출발은 어떤 서비스인지 알아보겠다. 1) 에이블리 에이블리는 온라인 동영상 서비스(OTT) ‘왓챠’의 공동 창업자 출신인 강석훈 대표가 세운 여성 패션 플랫폼이다. 출시 후 3년여 만에 누적 거래액 1조원, 누적 다운로..
2022.08.19
-
 AARRR이란?
1. 지표란? AARRR을 알아보기에 앞서, 지표 (metric)가 무엇인지 알아야 한다. 지표란 로그를 특정 기준에 따라서 요약한 숫자를 말한다. ex) 클릭 수 , 채택률, 문의 수 기존 업무에서 지표를 관리하는 방법은 Task - based 관리법이었다. AARRR을 알아보기 전에 간단히 알아보자. 2. Task - based 지표관리 (업무 별 지표관리) 마케팅팀의 업무,운영팀의 업무, 개발팀의 업무, 사업팀의 업무들에서 나온 지표의 숫자들을 살펴보는 관리법 2-1. 예시 마케팅 팀 : SNS 마케팅 : 이번 주 Facebook 광고의 ROAS(광고비에 대한 매출 비율)는 200% 입니다. 개발 팀 : 앱 업데이트 : 월요일에 배포한 버전 3.0의 채택률은 60%입니다. 운영 팀 : 사용자 문의/..
2022.08.05
AARRR이란?
1. 지표란? AARRR을 알아보기에 앞서, 지표 (metric)가 무엇인지 알아야 한다. 지표란 로그를 특정 기준에 따라서 요약한 숫자를 말한다. ex) 클릭 수 , 채택률, 문의 수 기존 업무에서 지표를 관리하는 방법은 Task - based 관리법이었다. AARRR을 알아보기 전에 간단히 알아보자. 2. Task - based 지표관리 (업무 별 지표관리) 마케팅팀의 업무,운영팀의 업무, 개발팀의 업무, 사업팀의 업무들에서 나온 지표의 숫자들을 살펴보는 관리법 2-1. 예시 마케팅 팀 : SNS 마케팅 : 이번 주 Facebook 광고의 ROAS(광고비에 대한 매출 비율)는 200% 입니다. 개발 팀 : 앱 업데이트 : 월요일에 배포한 버전 3.0의 채택률은 60%입니다. 운영 팀 : 사용자 문의/..
2022.08.05
-
 Superstore Sales Data - RFM 분석 프로젝트 및 쿼리
RFM이란? 회사 매출에 가장 중요한 인자를 R , F, M 으로 가정하여, 이 3가지 관점에서 고객의 가치를 분석하는 방법이다. R - Rencency : 최근 구매일 최근 무언가를 구매한 사용자를 우량 고객으로 취급 F - Frequency : 구매 횟수 사용자가 구매한 횟수를 세고, 많을수록 우량 고객으로 취급 M : Monetary : 구매 금액 합계 사용자의 구매 금액 합계를 집계하고, 금액이 높을수록 우량 고객으로 취급 위 세 가지 지표를 집계한 뒤에 고객군 별로 속성을 정의한다. 마케팅, 기획 팀은 서비스 개선을 검토하고, 고객에게 메일 최적화, 쿠폰 제공 등 고객군 별 맞춤 전략을 짜야한다. 데이터 셋 캐글 - Superstore Sales Dataset을 정제한 데이터 셋. https:/..
2022.06.24
Superstore Sales Data - RFM 분석 프로젝트 및 쿼리
RFM이란? 회사 매출에 가장 중요한 인자를 R , F, M 으로 가정하여, 이 3가지 관점에서 고객의 가치를 분석하는 방법이다. R - Rencency : 최근 구매일 최근 무언가를 구매한 사용자를 우량 고객으로 취급 F - Frequency : 구매 횟수 사용자가 구매한 횟수를 세고, 많을수록 우량 고객으로 취급 M : Monetary : 구매 금액 합계 사용자의 구매 금액 합계를 집계하고, 금액이 높을수록 우량 고객으로 취급 위 세 가지 지표를 집계한 뒤에 고객군 별로 속성을 정의한다. 마케팅, 기획 팀은 서비스 개선을 검토하고, 고객에게 메일 최적화, 쿠폰 제공 등 고객군 별 맞춤 전략을 짜야한다. 데이터 셋 캐글 - Superstore Sales Dataset을 정제한 데이터 셋. https:/..
2022.06.24
-
 [빅쿼리-SQL]고객 마스터 데이터를 카테고리화(성별,연령대)하여 집계하기
서비스를 제공하는 측에서 사용자와 관련된 정보로 알고 싶은 것을 정리해보면 다음과 같은 두 가지로 분류할 수 있습니다. 사용자의 속성(나이,성별,주소지) 사용자의 행동(구매한 상품, 사용한 기능, 사용하는 빈도) 이 중 사용자의 속성을 정리한 데이터를 '고객 마스터 데이터'라고 합니다. '고객 마스터 데이터'를 통하여 분석가는 '어떤 속성의 사용자가 우리 서비스를 사용 중인가?'를 알아볼 수 있습니다. 이번 글에서는 예제 '고객 마스터 데이터'를 사용하여 성별, 연령별로 구분하고 이를 '카테고리화' 하는 방법을 알아보겠습니다. 샘플 데이터 의 예제 데이터 셋을 사용하였습니다. 테이블 명 : mst_users user_ iD : 고객 ID Sex : 고객의 성별 birth_date : 고객의 생년월일 re..
2022.06.21
[빅쿼리-SQL]고객 마스터 데이터를 카테고리화(성별,연령대)하여 집계하기
서비스를 제공하는 측에서 사용자와 관련된 정보로 알고 싶은 것을 정리해보면 다음과 같은 두 가지로 분류할 수 있습니다. 사용자의 속성(나이,성별,주소지) 사용자의 행동(구매한 상품, 사용한 기능, 사용하는 빈도) 이 중 사용자의 속성을 정리한 데이터를 '고객 마스터 데이터'라고 합니다. '고객 마스터 데이터'를 통하여 분석가는 '어떤 속성의 사용자가 우리 서비스를 사용 중인가?'를 알아볼 수 있습니다. 이번 글에서는 예제 '고객 마스터 데이터'를 사용하여 성별, 연령별로 구분하고 이를 '카테고리화' 하는 방법을 알아보겠습니다. 샘플 데이터 의 예제 데이터 셋을 사용하였습니다. 테이블 명 : mst_users user_ iD : 고객 ID Sex : 고객의 성별 birth_date : 고객의 생년월일 re..
2022.06.21
-
 Pycaret을 사용한 간단한 머신러닝 모델 구축 프로젝트
Pycaret이란? scikit- learn 패키지를 기반으로, 자동으로 머신러닝 모델을 만들어 주는 파이썬 라이브러리. 몇줄의 코딩으로 쉽게 모든 모델 비교, 하이퍼파라미터 튜닝등을 할 수 있다. 머신러닝 모델 구축에 항상 어려움이 있었다면 Pycaret을 적극적으로 활용해보자! 데이터 준비 전자상거래 웹사이트 내 거래 데이터를 사용해 불법거래를 예측하는 기계학습 모델을 구축하기 위해 Electronica 전자제품 판매 사이트에서 제공된 유저의 첫번째 트렌젝션 정보 데이터(Fraud_Data)를 사용 - user_id : 유저 아이디 - signup_time : 유저가 계정을 생성 시각 - purchase_time : 유저가 상품을 구매한 시각 - device_id : 트랜젝션별 고유한 디바이스 아이디..
2022.06.13
Pycaret을 사용한 간단한 머신러닝 모델 구축 프로젝트
Pycaret이란? scikit- learn 패키지를 기반으로, 자동으로 머신러닝 모델을 만들어 주는 파이썬 라이브러리. 몇줄의 코딩으로 쉽게 모든 모델 비교, 하이퍼파라미터 튜닝등을 할 수 있다. 머신러닝 모델 구축에 항상 어려움이 있었다면 Pycaret을 적극적으로 활용해보자! 데이터 준비 전자상거래 웹사이트 내 거래 데이터를 사용해 불법거래를 예측하는 기계학습 모델을 구축하기 위해 Electronica 전자제품 판매 사이트에서 제공된 유저의 첫번째 트렌젝션 정보 데이터(Fraud_Data)를 사용 - user_id : 유저 아이디 - signup_time : 유저가 계정을 생성 시각 - purchase_time : 유저가 상품을 구매한 시각 - device_id : 트랜젝션별 고유한 디바이스 아이디..
2022.06.13
-
 그로스 해킹이란? - 리그 오브 레전드와 오버워치의 차이점
그로스 해킹이란? 데이터를 기반으로 서비스/비즈니스에서 마주한 문제를 풀어 제품 및 서비스를 지속적으로 개선시키고, 서비스의 성장/성공을 도모하는 것 우선, 성공하는 서비스를 만들기 위해서는 다음과 같은 항목이 필요하다. 1) 좋은 아이디어 2) 안정적인 개발 3) 예쁜 디자인 4) 효과적인 마케팅 하지만 이런 제품이 엄청난 속도로 제품 및 서비스가 생성되고 있는 상황에, 우리 제품이 선택되는 것은 하늘의 별따기인 상황 그렇다면 어떻게 하면 이 레드오션 속에서 성공할 수 있는가? 그 해답은 바로 '그로스해킹' 게임: 리그 오브 레전드(이하 롤)와 오버워치를 비교해보자 1. 롤 개요 : 명실상부 대한민국 대표 게임 현재 : 2012년 한국 론칭을 시작으로 2022년 현재까지 최고의 자리를 유지하고 있음 2..
2022.06.05
그로스 해킹이란? - 리그 오브 레전드와 오버워치의 차이점
그로스 해킹이란? 데이터를 기반으로 서비스/비즈니스에서 마주한 문제를 풀어 제품 및 서비스를 지속적으로 개선시키고, 서비스의 성장/성공을 도모하는 것 우선, 성공하는 서비스를 만들기 위해서는 다음과 같은 항목이 필요하다. 1) 좋은 아이디어 2) 안정적인 개발 3) 예쁜 디자인 4) 효과적인 마케팅 하지만 이런 제품이 엄청난 속도로 제품 및 서비스가 생성되고 있는 상황에, 우리 제품이 선택되는 것은 하늘의 별따기인 상황 그렇다면 어떻게 하면 이 레드오션 속에서 성공할 수 있는가? 그 해답은 바로 '그로스해킹' 게임: 리그 오브 레전드(이하 롤)와 오버워치를 비교해보자 1. 롤 개요 : 명실상부 대한민국 대표 게임 현재 : 2012년 한국 론칭을 시작으로 2022년 현재까지 최고의 자리를 유지하고 있음 2..
2022.06.05
-
 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[마무리]
이번 워크샵을 통해 AWS 서비스를 사용하여 데이터 추출,적재,변환,분석의 전반적인 과정을 경험하였습니다. AWS의 각 서비스가 어떠한 역할을 하는지 알고, 이를 조합하여 데이터 파이프라인을 구축 및 데이터 분석을 해볼 수 있는 값진 경험이었습니다. 워크샵을 통해 경험 한 것은 다음과 같습니다. 워크샵의 학습 결과 서버리스 데이터 레이크 아키텍처 설계 Amazon S3를 스토리지를 사용하여 데이터를 Data Lake로 수집하는 데이터 처리 파이프라인 구축 실시간 스트리밍 데이터에 Amazon Kinesis 사용 AWS Glue를 사용하여 데이터세트 자동 분류 AWS Glue 개발 엔드포인트에 연결된 Amazon SageMaker Jupyter 노트북에서 대화형 ETL 스크립트 실행 Glue에서 Amazo..
2022.05.30
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[마무리]
이번 워크샵을 통해 AWS 서비스를 사용하여 데이터 추출,적재,변환,분석의 전반적인 과정을 경험하였습니다. AWS의 각 서비스가 어떠한 역할을 하는지 알고, 이를 조합하여 데이터 파이프라인을 구축 및 데이터 분석을 해볼 수 있는 값진 경험이었습니다. 워크샵을 통해 경험 한 것은 다음과 같습니다. 워크샵의 학습 결과 서버리스 데이터 레이크 아키텍처 설계 Amazon S3를 스토리지를 사용하여 데이터를 Data Lake로 수집하는 데이터 처리 파이프라인 구축 실시간 스트리밍 데이터에 Amazon Kinesis 사용 AWS Glue를 사용하여 데이터세트 자동 분류 AWS Glue 개발 엔드포인트에 연결된 Amazon SageMaker Jupyter 노트북에서 대화형 ETL 스크립트 실행 Glue에서 Amazo..
2022.05.30
-
 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[6]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[5] 실습과정 미리보기 Amazon Redshift 클러스터를 설정하고 S3 데이터를 Amazon Redshift로 로드 1. Redshift IAM Role 생성 이 단계에서는 Redshift 클러스터를 위한 IAM Role을 생성합니다. Create role 클릭 Redshift 선택 Select your use case 아래의 Redshift - customizable 선택 Next: Permissions 클릭 검색 박스에서 정책을 검색 및 선택 AmazonS3FullAccess AWSGlueConsoleFullAccess (워크샵에서는 glue에 접근하기에 필요합니다.) Next: Review 클릭 R..
2022.05.30
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[6]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[5] 실습과정 미리보기 Amazon Redshift 클러스터를 설정하고 S3 데이터를 Amazon Redshift로 로드 1. Redshift IAM Role 생성 이 단계에서는 Redshift 클러스터를 위한 IAM Role을 생성합니다. Create role 클릭 Redshift 선택 Select your use case 아래의 Redshift - customizable 선택 Next: Permissions 클릭 검색 박스에서 정책을 검색 및 선택 AmazonS3FullAccess AWSGlueConsoleFullAccess (워크샵에서는 glue에 접근하기에 필요합니다.) Next: Review 클릭 R..
2022.05.30
-
 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[5]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[4] 실습과정 미리보기 람다 함수를 작성하여 Athena가 S3의 processsed data에서 Hits 별 Top 5 Popular Songs를 쿼리하고 가져 오는 코드를 호스팅 서비스명 서비스 설명 비고 AWS Athena Amazon Athena는 표준 SQL을 사용해 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스 Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불함 AWS Lambda AWS Labmda는 서버를 관리하지 않고도 코드를 실행할 수 있는 AWS에서 제공하는 서버리스 컴퓨팅 서비스 서버리스란? 서버가 없는것이 아니라 서버에 대한 요청을 처..
2022.05.30
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[5]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[4] 실습과정 미리보기 람다 함수를 작성하여 Athena가 S3의 processsed data에서 Hits 별 Top 5 Popular Songs를 쿼리하고 가져 오는 코드를 호스팅 서비스명 서비스 설명 비고 AWS Athena Amazon Athena는 표준 SQL을 사용해 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스 Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불함 AWS Lambda AWS Labmda는 서버를 관리하지 않고도 코드를 실행할 수 있는 AWS에서 제공하는 서버리스 컴퓨팅 서비스 서버리스란? 서버가 없는것이 아니라 서버에 대한 요청을 처..
2022.05.30
-
 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[4]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[3] 실습과정 미리보기 Amazon Athena의 표준 SQL 쿼리를 사용하여 Glue 카탈로그에 등록된 데이터를 탐색 Athena를 사용하여 Amazon Quicksight에서 대시보드/시각화를 구축 서비스명 서비스 설명 비고 AWS Athena Amazon Athena는 표준 SQL을 사용해 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스 Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불함 AWS Quicksight Amazon QuickSight는 아마존이 제공하는 서버리스 매니지드 BI 상품. 특정 데이터에 대한 시각화 대시보드를 생성하고 다른 사용자와..
2022.05.29
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[4]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[3] 실습과정 미리보기 Amazon Athena의 표준 SQL 쿼리를 사용하여 Glue 카탈로그에 등록된 데이터를 탐색 Athena를 사용하여 Amazon Quicksight에서 대시보드/시각화를 구축 서비스명 서비스 설명 비고 AWS Athena Amazon Athena는 표준 SQL을 사용해 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스 Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불함 AWS Quicksight Amazon QuickSight는 아마존이 제공하는 서버리스 매니지드 BI 상품. 특정 데이터에 대한 시각화 대시보드를 생성하고 다른 사용자와..
2022.05.29
-
 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[3]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[2] 실습과정 미리보기 AWS Glue ETL을 사용하여 데이터를 처리하고 결과를 다시 S3에 저장 Glue 개발 엔드포인트와 Sagemaker 노트북을 사용하여 데이터 변환 단계를 진행(PySpark) 서비스명 서비스 설명 비고 AWS Glue dev endpoint AWS Glue 스크립트를 개발하고 테스트할 수 있는 환경 엔드포인트가 데이터 스토어에 액세스한 후 개발 엔드포인트에 연결하는 노트북을 생성. 노트북을 사용하여 ETL 스크립트를 작성하고 테스트할 수 있습니다. AWS SageMaker jupyter notebook과 동일한 환경이나 aws 클라우드 플랫폼 1. AWS Glue Dev Endpo..
2022.05.28
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[3]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[2] 실습과정 미리보기 AWS Glue ETL을 사용하여 데이터를 처리하고 결과를 다시 S3에 저장 Glue 개발 엔드포인트와 Sagemaker 노트북을 사용하여 데이터 변환 단계를 진행(PySpark) 서비스명 서비스 설명 비고 AWS Glue dev endpoint AWS Glue 스크립트를 개발하고 테스트할 수 있는 환경 엔드포인트가 데이터 스토어에 액세스한 후 개발 엔드포인트에 연결하는 노트북을 생성. 노트북을 사용하여 ETL 스크립트를 작성하고 테스트할 수 있습니다. AWS SageMaker jupyter notebook과 동일한 환경이나 aws 클라우드 플랫폼 1. AWS Glue Dev Endpo..
2022.05.28
-
 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[2]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[1] 실습과정 간단 정리 s3에 저장된 데이터를 크롤러의 도움을 받아서 글루 데이터 카탈로그에 등록 서비스명 서비스 설명 비고 Amazon Glue 원본 데이터에서 크롤러를 정의하여 테이블 형태로 aws glue data catalog를 채운다. 데이터 카탈로그란? s3의 데이터를 테이블처럼 만드는 것을 카탈로그로 만든다고 함. 데이터를 글루데이터 카탈로그에 등록시켜 놓으면 aws의 다른 분석 서비스에서 활용 할 수 있음 Amazon Athena aws의 대화형 대화형 쿼리 서비스 1. IAM 역할 생성 aws glue 서비스를 사용하기 전 iam 콘솔로 이동하여 권한을 정의해야 함 create role - ..
2022.05.27
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍[2]
전제조건 [AWS] AWS 기반 데이터 파이프라인 구축 - Analytics on AWS 워크숍[1] 실습과정 간단 정리 s3에 저장된 데이터를 크롤러의 도움을 받아서 글루 데이터 카탈로그에 등록 서비스명 서비스 설명 비고 Amazon Glue 원본 데이터에서 크롤러를 정의하여 테이블 형태로 aws glue data catalog를 채운다. 데이터 카탈로그란? s3의 데이터를 테이블처럼 만드는 것을 카탈로그로 만든다고 함. 데이터를 글루데이터 카탈로그에 등록시켜 놓으면 aws의 다른 분석 서비스에서 활용 할 수 있음 Amazon Athena aws의 대화형 대화형 쿼리 서비스 1. IAM 역할 생성 aws glue 서비스를 사용하기 전 iam 콘솔로 이동하여 권한을 정의해야 함 create role - ..
2022.05.27
-
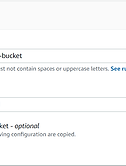 [AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍 [1]
전제조건 AWS 계정에서 AdminstratorAccess에 대한 액세스 권한이 있어야합니다. 이 실습은 us-east-1 리전에서 실행되어야 합니다. 이 가이드의 링크에 따라 새 탭에서 여는 것이 가장 좋습니다. 최신 브라우저에서 이 실습을 실행하세요. 실습과정 간단 정리 Raw 데이터 추출,변환,적재 사용되는 서비스명 서비스 설명 비고 Amazon Kinesis Data Firehose 스트리밍 데이터를 안정적으로 캡처하고 변환하여 데이터 레이크에 전달하는 추출, 변환 로드 서비스 스트리밍 데이터란? 고객,애플리케이션,시스템에서 실시간으로 생성되는 데이터 Amazon S3 클라우드 객체 스토리지 서비스 1. S3 버킷 생성하기 데이터를 적재하기 위한 저장소를 만들어 주기 위해 S3 버킷을 생성한다. ..
2022.05.24
[AWS]AWS 기반 데이터분석 파이프라인 구축 - Analytics on AWS 워크숍 [1]
전제조건 AWS 계정에서 AdminstratorAccess에 대한 액세스 권한이 있어야합니다. 이 실습은 us-east-1 리전에서 실행되어야 합니다. 이 가이드의 링크에 따라 새 탭에서 여는 것이 가장 좋습니다. 최신 브라우저에서 이 실습을 실행하세요. 실습과정 간단 정리 Raw 데이터 추출,변환,적재 사용되는 서비스명 서비스 설명 비고 Amazon Kinesis Data Firehose 스트리밍 데이터를 안정적으로 캡처하고 변환하여 데이터 레이크에 전달하는 추출, 변환 로드 서비스 스트리밍 데이터란? 고객,애플리케이션,시스템에서 실시간으로 생성되는 데이터 Amazon S3 클라우드 객체 스토리지 서비스 1. S3 버킷 생성하기 데이터를 적재하기 위한 저장소를 만들어 주기 위해 S3 버킷을 생성한다. ..
2022.05.24





























